Data from VTune / Final Thoughts for Tonight
So part of my other future goals from yesterday was to get some profiler working. I’ve used VTune in the past on Intel machines to high level of success, but I’d had trouble in some cases with AMD hardware. It’s been a while since I’ve tried that, but luckily it installed and worked pretty flawlessly off the bat. This gave me some good information that confirmed some of my assumptions from yesterday.
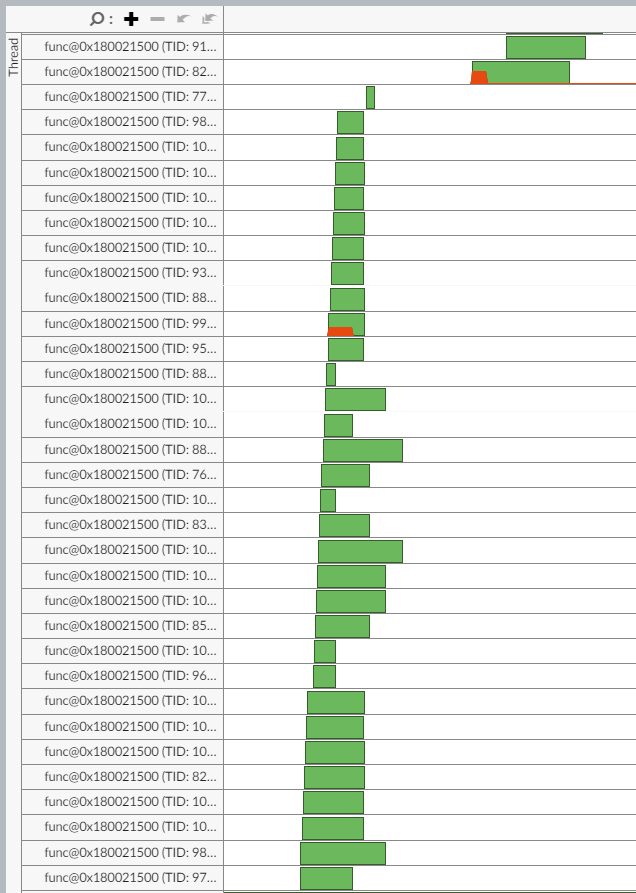
This first picture is a piece of the thread graph from yesterday’s iteration one. What it’s showing is that I can get a lot of threads running in parallel together, but it confirms that I’ve got some problems:
- The threads never really run a large amount of work at once to stress the machine, so I’m wasting a lot of cycles.
- The threads spend a (relatively) high amount of time just waiting on other threads to complete.
- This leaves a big gap before the next block of threads can get started.
And yes, the gaps are exacerbated by the presence of the profiler, but it just further proved my assumptions in that I don’t want to introduce places where I’m just waiting on stuff.

This picture is the thread graph from the second iteration test yesterday. It shows a fairly nice use of the entire CPU as the threads come online and start operating on their work unit. However, the threads end at hugely varying times based on whether or not they crunch through their work or get stuck waiting on something else on their core. It’s a distinct improvement, but it would get worse once I add reflection/refraction and make the work units non-fixed in size.
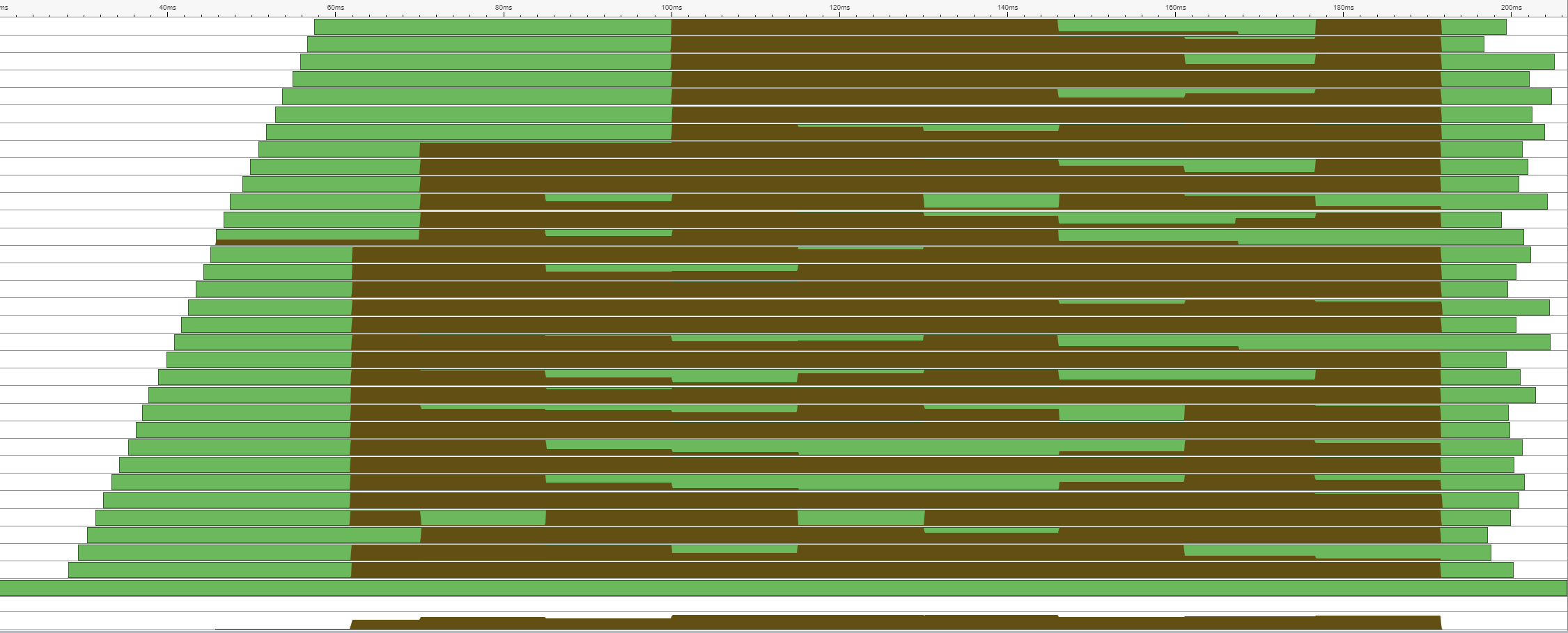
This final image is the iteration from tonight. What we’ve now got is a situation where the threads are all there, but they can work a lot more efficiently based on the resources that they’re given. Threads spinning up later simply do less work. Threads that get blocked by other system resource needs can slow down. However, overall we’ve got a much more consistent period of running at higher total CPU utilization. Importantly, the threads also all manage to finish significantly closer together, minimizing my time spent waiting on them to complete at the end.
This particular variation is what I’ll be using when I move forward with my next set of features in the ray tracer, and at that point I also plan on comparing the performance of a row as a work unit vs. a pixel as a work unit to see if this new pattern is more conducive to that smaller work unit.